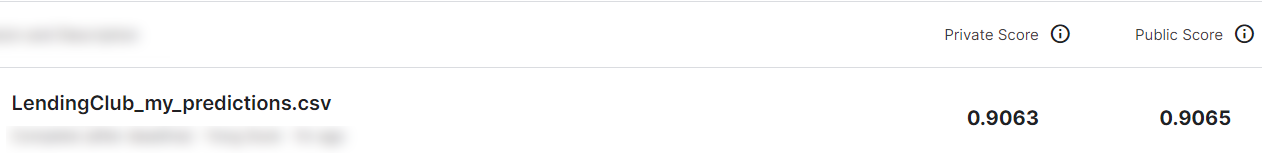AI200_ML_Classification_Project_LendingClubLoanDefaultersPrediction
Loan Defaulter Machine Learning Classification [Python, scikit-learn, Applied Machine Learning]
| View JupyterNoteBook | GitHub Repository Link |
Background
Business Case: Develop a Machine Learning model for the company to identify if the loan applicant is likely or unlikely to default on the loan, thereby assisting in the company’s portfolio & risk assessment capabilities
Exploratory Data Analysis [EDA], feature-engineering & model testing was conducted using Python within the JupyterNotebook environment. Various feature engineering techniques & models were experimented & the best AUC scoring model was then selected & applied to form the final model.
The final model, along with the feature-engineered dataframe, acheived a ~90% predictive AUC score after cross-validation via the Kaggle platform, thus demonstrating a strong ablity to discriminate between loan applicants whom are likely or unlikely to default on loans.
.png)
Overview of steps undertaken for the project
1) Data Preparation
Train & Test dataframes were imported into the notebook.
Target feature ‘loan_status’ was transformed into binary form with function `change_loan_status’. ‘1’ represents loan applicants whom have defaulted, and vice versa
Focus was placed on EDA, feature-engineering, ML model testing via train_test_split & K-Fold cross validation on train_df dataset first. I proceeded to apply the same feature-engineering steps on test_df, once a high scoring AUC model was derived & achieved on train_df.
2) Exploratory Data Analysis
In this phase, I utilized packages such as missingno & libraries such as seaborn for data visualization. The main goal was to:
- Detect which columns had missing values, so that appropriate feature-engineering steps can be taken for those columns. This was achieved with the missingno package
- Determine which numerical features are important via pairplot/ correlational heatmap
- Determine which categorical features are important with Chi-squared & P-Value calculations
3) Feature Engineering
In this phase, I first focused on dealing with missing values in both categorical & numerical columns.
For categorical columns with missing features, I investigated imputational techniques such as:
a) One hot encoding
b) Label encoding
c) Mode imputation
d) Feature Hashing
For numerical columns with missing features, I investigated imputational techniques such as:
a) Mean Imputation
b) Median Imputation
Next, I selected & enhanced relevant features through data transformation techniques. This was done through the creation and application of a function to extract and create the feature zip_code from the address column.
Columns that were deemed to have potential risks of data leakage were removed as well.
Additional EDA on the feature engineered zip_code column was performed.
Finally, all decided feature-engineering steps was performed on the train_df dataframe before proceeding to the next section.
4) Model Building & Model Evaluation
In this section, the feature-engineered train_df was tested with both Non-Ensemble [LogisticRegression, Decision Tree Classifier] & Ensemble Models [Random Forest Classifier, XGBClassifier, CatBoost].
The baseline CatBoost model had the highest average AUC score amongst all other models tested. Following that, I proceeded to apply hyperparameter tuning of the model via GridSearchCV.
5) Generate and Export Predictions from Final Model
The final chosen model & parameters was retrained & fitted using all 316824 rows of the entire training set (instead of just on X_train, y_train with train_test_split).
All feature-engineering techniques that was previously applied to train_df was then applied to test_df.
Next, prediction probabilities were generated on the final_test dataframe using the fitted model.
Finally, the prediction probabilities were outputted to a .csv file & uploaded to the Kaggle platform, where my model’s prediction was compared to the actual (hidden) labels to determine how well it perfroms on unseen data.